
For run time complexity analysis we use big Oh notation extensively so it is vital that you are familiar with the general concepts to determine which is the best algorithm for you in certain scenarios. We have chosen to use big Oh notation for a few reasons, the most important of which is that it provides an abstract measurement by which we can judge the performance of algorithms without using mathematical proofs.

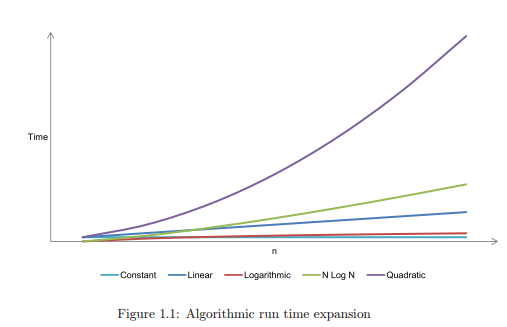
Figure 1.1 shows some of the run times to demonstrate how important it is to choose an efficient algorithm. For the sanity of our graph we have omitted cubic O(n 3 ), and exponential O(2n) run times. Cubic and exponential algorithms should only ever be used for very small problems (if ever!); avoid them if feasibly possible.
The following list explains some of the most common big Oh notations:
O(1) constant: the operation doesn’t depend on the size of its input, e.g. adding a node to the tail of a linked list where we always maintain a pointer to the tail node.
O(n) linear: the run time complexity is proportionate to the size of n.
O(log n) logarithmic: normally associated with algorithms that break the problem into smaller chunks per each invocation, e.g. searching a binary search tree.
O(n log n) just n log n: usually associated with an algorithm that breaks the problem into smaller chunks per each invocation, and then takes the results of these smaller chunks and stitches them back together, e.g. quick sort.
O(n 2 ) quadratic: e.g. bubble sort.
O(n 3 ) cubic: very rare.
O(2n) exponential: incredibly rare.
If you encounter either of the latter two items (cubic and exponential) this is really a signal for you to review the design of your algorithm. While prototyping algorithm designs you may just have the intention of solving the problem irrespective of how fast it works. We would strongly advise that you always review your algorithm design and Optimize where possible—particularly loops and recursive calls—so that you can get the most efficient run times for your algorithms. The biggest asset that big Oh notation gives us is that it allows us to essentially discard things like hardware. If you have two sorting algorithms, one with a quadratic run time, and the other with a logarithmic run time then the logarithmic algorithm will always be faster than the quadratic one when the data set becomes suitably large. This applies even if the former is ran on a machine that is far faster than the latter. Why? Because big Oh notation isolates a key factor in algorithm analysis: growth. An algorithm with a quadratic run time grows faster than one with a logarithmic run time. It is generally said at some point as n → ∞ the logarithmic algorithm will become faster than the quadratic algorithm. Big Oh notation also acts as a communication tool. Picture the scene: you are having a meeting with some fellow developers within your product group. You are discussing prototype algorithms for node discovery in massive networks. Several minutes elapse after you and two others have discussed your respective algorithms and how they work. Does this give you a good idea of how fast each respective algorithm is? No. The result of such a discussion will tell you more about the high level algorithm design rather than its efficiency. Replay the scene back in your head, but this time as well as talking about algorithm design each respective developer states the asymptotic run time of their algorithm. Using the latter approach you not only get a good general idea about the algorithm design, but also key efficiency data which allows you to make better choices when it comes to selecting an algorithm fit for purpose. Some readers may actually work in a product group where they are given budgets per feature. Each feature holds with it a budget that represents its uppermost time bound. If you save some time in one feature it doesn’t necessarily give you a buffer for the remaining features. Imagine you are working on an application, and you are in the team that is developing the routines that will essentially spin up everything that is required when the application is started. Everything is great until your boss comes in and tells you that the start up time should not exceed n ms. The efficiency of every algorithm that is invoked during start up in this example is absolutely key to a successful product. Even if you don’t have these budgets you should still strive for optimal solutions. Taking a quantitative approach for many software development properties will make you a far superior programmer – measuring one’s work is critical to success.
In The Next part we study about Imperative programming language so keep watching my post
Nggak Nyangka! Hidup Gue Berubah Total! Gue bukan siapa-siapa. Cuma anak kos biasa yang kerja serabutan buat nutup biaya hidup… Read More
What is the Main Cause of a Heart Attack? What is its Solution? A heart attack is the blockage of… Read More
In the vast economic arena, one term that often takes center stage, inciting extensive debates and discussions, is the "debt… Read More
De-Dollarization: The Changing Face of Global Finance The financial landscape is in a state of flux, with an intriguing economic… Read More
The curtains closed on a dramatic Bundesliga season with Bayern Munich standing tall once again, clinching their 11th straight title.… Read More
The Unfolding Story of Celine Dion's Health In recent news that has left fans across the globe stunned, iconic singer… Read More



